Stack
스택의 개념
스택(stack)이란 쌓아 올린다는 것을 의미한다.
따라서 스택 자료구조라는 것은 책을 쌓는 것처럼 차곡차곡 쌓아 올린 형태의 자료구조를 말한다.
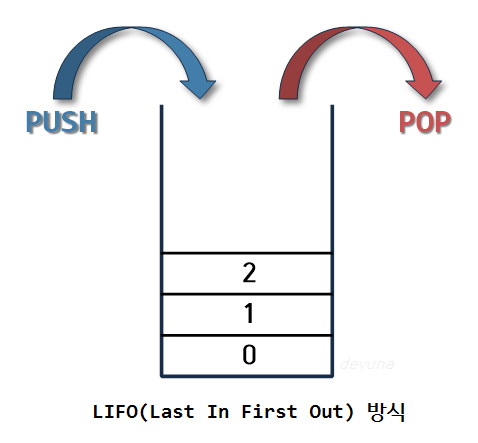
스택의 특징
- 스택은 위의 사진처럼 같은 구조와 크기의 자료를 정해진 방향으로만 쌓을수 있고, top으로 정한 곳을 통해서만 접근할 수 있다.
- top에는 가장 위에 있는 자료는 가장 최근에 들어온 자료를 가리키고 있으며,삽입되는 새 자료는 top이 가리키는 자료의 위에 쌓이게 된다.
- 스택에서 자료를 삭제할 때도 top을 통해서만 가능하다.
- 스택에서 top을 통해 삽입하는 연산을 'push' , top을 통한 삭제하는 연산을 'pop'이라고 한다.
따라서 스택은 시간 순서에 따라 자료가 쌓여서 가장 마지막에 삽입된 자료가 가장 먼저 삭제된다는
구조적 특징을 가지게 된다.
이러한 스택의 구조를 후입선출(LIFO, Last-In-First-Out) 구조이라고 한다.
그리고 비어있는 스택에서 원소를 추출하려고 할 때 stack underflow라고 하며,
스택이 넘치는 경우 stack overflow라고 한다.
스택의 활용 예시
스택의 특징인 후입선출(LIFO)을 활용하여 여러 분야에서 활용 가능하다.
- 웹 브라우저 방문기록 (뒤로 가기) : 가장 나중에 열린 페이지부터 다시 보여준다.
- 역순 문자열 만들기 : 가장 나중에 입력된 문자부터 출력한다.
- 실행 취소 (undo) : 가장 나중에 실행된 것부터 실행을 취소한다.
- 후위 표기법 계산
- 수식의 괄호 검사 (연산자 우선순위 표현을 위한 괄호 검사)
스택 활용 기본 알고리즘( 백준 10828번)
public class Main {
public static int[] stack;
public static int size = 0;
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
StringBuilder sb = new StringBuilder();
int N = in.nextInt();
stack = new int[N];
for(int i = 0; i < N; i++) {
String str = in.next();
switch (str) {
case "push":
push(in.nextInt());
break;
case "pop":
sb.append(pop()).append('\n');
break;
case "size":
sb.append(size()).append('\n');
break;
case "empty":
sb.append(empty()).append('\n');
break;
case "top":
sb.append(top()).append('\n');
break;
}
}
System.out.println(sb);
}
public static void push(int item) {
stack[size] = item;
size++;
}
public static int pop() {
if(size == 0) {
return -1;
}
else {
int res = stack[size - 1];
stack[size - 1] = 0;
size--;
return res;
}
}
public static int size() {
return size;
}
public static int empty() {
if(size == 0) {
return 1;
}
else {
return 0;
}
}
public static int top() {
if(size == 0) {
return -1;
}
else {
return stack[size - 1];
}
}
}
Queue
큐의 개념
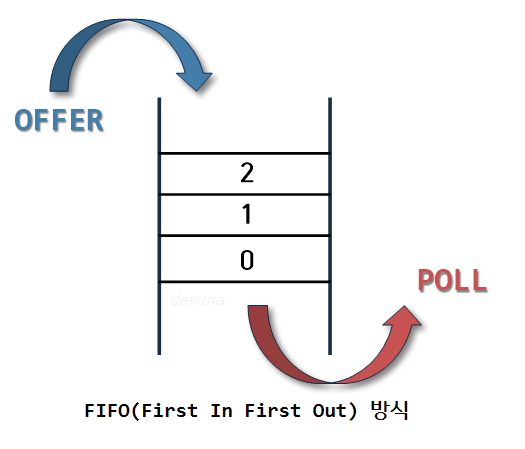
Queue 의 사전적 의미는 1. (무엇을 기다리는 사람, 자동차 등의) 줄 , 혹은 줄을 서서 기다리는 것을 의미한다.
따라서 일상생활에서 놀이동산에서 줄을 서서 기다리는 것, 은행에서 먼저 온 사람의 업무를 창구에서 처리하는 것과 같이
선입선출(FIFO, First in first out) 방식의 자료구조를 말한다.
큐의 특징
정해진 한 곳(top)을 통해서 삽입, 삭제가 이루어지는 스택과는 달리
큐는 한쪽 끝에서 삽입 작업이, 다른 쪽 끝에서 삭제 작업이 양쪽으로 이루어진다.
이때 삭제연산만 수행되는 곳을 프론트(front), 삽입연산만 이루어지는 곳을 리어(rear)로 정하여
각각의 연산작업만 수행된다. 이때, 큐의 리어에서 이루어지는 삽입연산을 인큐(enQueue)
프론트에서 이루어지는 삭제연산을 디큐(dnQueue)라고 부른다.
- 큐의 가장 첫 원소를 front / 가장 끝 원소를 rear
- 큐는 들어올 때 rear로 들어오지만 나올때는 front부터 빠지는 특성
- 접근방법은 가장 첫 원소와 끝 원소로만 가능
- 가장 먼저 들어온 프론트 원소가 가장 먼저 삭제
즉, 큐에서 프론트 원소는 가장 먼저 큐에 들어왔던 첫 번째 원소가 되는 것이며,
리어 원소는 가장 늦게 큐에 들어온 마지막 원소가 되는 것이다.
큐의 활용 예시
큐는 주로 데이터가 입력된 시간 순서대로 처리해야 할 필요가 있는 상황에 이용한다.
- 우선순위가 같은 작업 예약 (프린터의 인쇄 대기열)
- 은행 업무
- 콜센터 고객 대기시간
- 프로세스 관리
- 너비 우선 탐색(BFS, Breadth-First Search) 구현
- 캐시(Cache) 구현
Deque
덱의 개념
삽입과 삭제가 리스트의 양쪽 끝에서 모두 발생할 수 있는 자료구조이다.
스택과 큐의 장점만 따서 구성한 것으로서, 입력이 한쪽에서만 발생하고 출력은 양쪽에서 일어날 수 있는 입력 제한과 입력은 양쪽에서 일어나고 출력은 한곳에서만 이루어지는 출력 제한이 있다.

스택과 큐의 java 코드 및 실행결과

스택과 큐 코드 실행결과
'CS > 자료구조' 카테고리의 다른 글
| 자료 구조 - 해시 테이블(HashTable) (0) | 2023.10.29 |
|---|---|
| [Data Structure] Linked List (0) | 2021.09.15 |
| [Data Structure] 자료구조란? (0) | 2021.09.01 |
| [Data Structure] 버블 정렬(Bubble sort) (0) | 2021.03.22 |